
AG est une entreprise qui gère un énorme volume de données. Notre nouvelle data platforme révolutionne l’ approche des défis auxquels nous faisons face. Exemple concret : notre gestion des terribles inondations de 2021. L’alignement avec les objectifs stratégiques de la compagnie, l’amélioration des connaissances liées aux données et les technologies avancées comme Python, R, PowerBI et la plateforme Azure nous permettent de capitaliser sur les data et nous propulsent vers un avenir riche en possibilités en matière de GenAI et de machine learning.

TOM DONAS
Head of Business Solutions Data Intelligence
Les data au cœur de notre métier
Les données sont au cœur du métier de l’assurance. Dans notre secteur, de nombreuses décisions relatives au développement de produits et à la tarification reposent traditionnellement sur des données. Depuis quelques années, nous utilisons des types de données plus variés et en plus grande quantité. Les données nous permettent d’améliorer notre gestion des sinistres, nos stratégies de vente, nos processus opérationnels et toutes les autres facettes de nos activités.

De nombreux événements témoignent de cette évolution, comme la manière dont nous avons géré de manière proactive les sinistres liés aux inondations de 2021. Ces inondations historiques ont eu un impact sur des centaines de milliers, voire des millions de Belges. Nous avons cartographié les dégâts, en utilisant toute une série de variables et de données, notamment les régions inondées, les habitations dans ces régions, leur proximité et leur altitude par rapport à une masse d’eau présentant des risques d’inondation, etc.
De fortes pluies ont emporté des voitures, les laissant éparpillées à travers la ville. Photo de Julie Lust pour Sky News.
Ensuite, nous avons créé un modèle qui permet d’estimer le nombre d’habitations touchées et les dommages prévisibles. Notre estimation de 1,5 à 2 milliards d’euros de sinistres a été vérifiée. Le montant total des sinistres pour les maisons traditionnelles s’élevant à 1,9 milliard d’euros pour l’ensemble du secteur de l’assurance.
La gestion de cette crise a été colossale pour plusieurs raisons :
- Nous avons contacté proactivement nos clients pour leur fournir une évaluation détaillée de leurs dommages. Cela a facilité le processus de traitement des sinistres et a permis d’effectuer plus rapidement les paiements pendant une période stressante. Grâce à des données précises, nous avons pu trouver rapidement une solution qui a bénéficié à tous les sinistrés concernés.
- Nous avons partagé avec le gouvernement et les autorités régionales les connaissances issues de notre modèle et de notre expérience afin d’évaluer correctement les zones et les citoyens impactés.
- Le coût astronomique des inondations a dépassé un certain seuil, obligeant le gouvernement à participer au règlement des dommages. Notre modèle détaillé a facilité les discussions avec le gouvernement au niveau national.
- Enfin, cet événement a également servi de sonnette d’alarme dans notre secteur, car nous étions le seul assureur capable de fournir ces informations. Cette situation a démontré le rôle essentiel des données en temps de crise.
Cette gestion efficace n’aurait pas été possible sans nos processus axés de longue date sur les data et sans nos compétences analytiques pointues. Nous avons capitalisé sur des processus qui placent constamment les données au cœur de l’ensemble de notre chaîne de valeur.
Les data doivent refléter les stratégies business
Les données doivent avoir un impact positif sur les résultats de l’entreprise. Nous veillons donc à ce que notre stratégie en matière de data soit alignée sur la stratégie globale de la compagnie. Notre ambition est claire : nous voulons continuer à fournir des applications, des systèmes et des produits qui répondent aux attentes de nos collaborateurs et de nos clients.
Au sein d’AG, nos collègues nous facilitent la tâche en intégrant les données comme un élément central de leurs projets et en nous impliquant dès le début. Nos analyses les aident à créer des applications pertinentes et conviviales, ainsi qu’à améliorer les processus d’entreprise. Encore mieux : ils adhèrent pleinement à cette approche centrée sur les data et la soutiennent activement.
Dans cette perspective, nous identifions des use cases qui répondent aux objectifs et aux besoins de nos partenaires. En définissant des projets data axés sur le business, nous maximisons la rentabilité de nos efforts et aidons nos collègues à évaluer la valeur ajoutée de nos initiatives en matière de données.
Améliorer les connaissances des données pour les faire adopter
Comprendre la valeur de nos projets data et de nos données est aussi crucial que l’alignement stratégique. Nos collègues, pas toujours familiers avec les données, ne soutiendront nos efforts que s’ils les comprennent. C’est pourquoi nous avons mis en place des sessions de formation avec l’équipe de Patrick Sergysels, Head of Data Management. Lors de ces sessions, nos collègues apprennent les principes fondamentaux de la propriété et de la gouvernance des données. Ils se familiarisent également avec les outils nécessaires pour démêler la complexité des data et sont sensibilisés à l’importance et aux conséquences de leur rôle en tant que gestionnaires de données.
Le reporting constitue le deuxième pilier crucial de l’adoption des données. Nous nous engageons à fournir des rapports de données fiables et accessibles en temps opportun. Pour que les données deviennent un élément central de nos processus, il est essentiel que nos collègues des différentes unités commerciales comprennent le potentiel des data et maîtrisent les rapports spécifiques aux projets.
La qualité, un élément essentiel
De nombreuses organisations qui cherchent à adopter une approche centrée sur les données se heurtent souvent à des problèmes de fiabilité de leurs data. Ce manque de fiabilité constitue le principal obstacle à l’instauration d’une culture axée sur les données. Pour y remédier, nous avons mis en place diverses mesures comportementales et technologiques visant à améliorer la qualité des données. Nous avons établi des normes de qualité plus strictes pour la saisie des données et intégré les paramètres et métadonnées correspondants sur notre nouvelle data platform. Nos business units sont tenues de respecter ces normes. De plus, nous avons instauré un système de signalement qui détecte les anomalies de saisie et identifie les schémas suspects dans les pipelines de données.
La technologie en guise de facilitateur
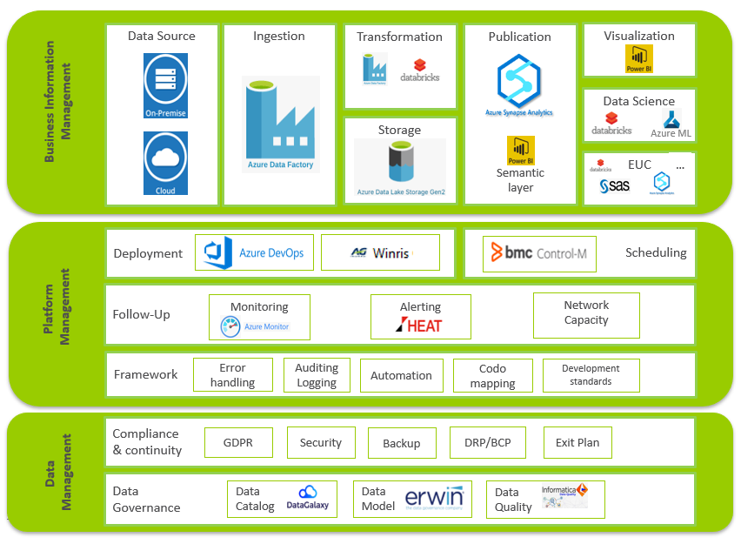
Bien que ces efforts soient le fruit du travail de qualité de nos data scientists et ingénieurs, la technologie joue un formidable rôle de facilitateur. Ces dernières années, nous avons utilisé des outils tels que Python, R, PowerBI, entre autres. En 2023, nous avons entrepris de migrer nos systèmes de données d’une plateforme SAS sur site vers le cloud. Cette migration visait à pouvoir stocker et traiter efficacement de grands volumes de données structurées et non structurées, à renforcer notre évolutivité et à fournir les services attendus par nos collègues et nos clients.
Notre nouvelle plateforme a été développée avec Microsoft Azure Synapse Analytics, en mettant l’accent sur l’automatisation, la standardisation et la rentabilité. Notre architecture intègre Azure Databricks et Azure Data Lake Storage Gen2 pour traiter de grands volumes de données. Nous utilisons Azure SQL DB pour l’automatisation des données, Synapse Dedicated SQL pools pour la distribution, et Azure Data Factory pour le mappage des flux de données et les processus ETL. De plus, nos collègues ont mis en place un espace de libre-service avec Microsoft Power BI et Azure pour les utilisateurs finaux, et ont créé un cadre PySpark personnalisé pour une gestion efficace des données.
Regards tournés vers l'avenir
Notre plateforme basée sur le cloud et notre nouvelle infrastructure adaptée au cloud nous permettent d’exploiter de nouveaux outils et des technologies émergentes telles que l’IA générative et le Machine Learning. Grâce à ces technologies, nous pouvons exploiter des données non structurées jusque-là sous-utilisées et transformer des rêves futuristes en applications réalisables. L’IA générative et le ML transformeront tout ce qui nous entoure en données exploitables.
Prenons l’exemple de la gestion des sinistres automobiles. Nous voulons créer un modèle qui utilise des données non structurées pour évaluer le type et le coût des dommages sur la base de photos envoyées par le client. Ensuite, le modèle pourrait interpréter l’image et la compare à notre base de données existante pour évaluer l’étendue des dommages. Il pourrait alors entamer les étapes du règlement de sinistres pour le client, qu’il s’agisse de prendre rendez-vous chez un carrossier ou avec un expert en assurance.
Outre l’automatisation des processus d’indemnisation, je m’attends à ce que les technologies émergentes modifient la façon dont nous travaillons avec les données. La création manuelle de rapports de données relèvera du passé et sera entièrement automatisée. Nous pourrons interagir avec un chatbot, demander un reporting détaillé et l’obtenir instantanément. Les données et les informations vont donc se démocratiser, ce qui permettra à nos business units d’obtenir des informations claires et complètes en un clin d’œil. La prise de décision centrée sur les données deviendra la norme en raison de l’omniprésence des données et de la vitesse à laquelle elles seront traitées.
Conclusion
Rétrospectivement, nous avons fait des pas de géant dans la transformation d’AG en une entreprise axée sur les data. Comme l’ont montré certains de nos projets novateurs, tels que les processus d’indemnisation pendant les inondations, AG est prête à adopter pleinement les données pour en faire une pièce maîtresse de ses processus. Après avoir jeté les bases technologiques pour tirer parti de GenAI et de ML pour de futurs projets, nous sommes impatients de voir ce que l’avenir nous réserve. Nous vous tiendrons au courant des nouvelles avancées importantes sur l’IT Hub.