Klanten bepalen alles. Nu zij steeds vaker digitale dienstverlening verwachten, hebben we grote hoeveelheden data nodig om gepersonaliseerde en gebruiksvriendelijke digitale diensten aan te bieden. Ons on-premises dataplatform bleek echter een knelpunt te zijn. Omdat we de nodige enorme hoeveelheden data niet efficiënt konden verwerken, bouwden we een dataplatform in de cloud. Ontdek hoe we dat gedaan hebben en hoe we er nu al de vruchten van plukken.

Patrick Sergysels
Head of Data Management
Chief Information Security Officer
Veranderende klantenbehoeften
Klanten rekenen op frictieloze en gepersonaliseerde digitale dienstverlening. Vooral tijdens stressvolle momenten. We doen er alles aan om aan deze behoeften te voldoen, maar daarvoor moeten we onze klanten zo goed mogelijk begrijpen. De sleutel daartoe is een enorme hoeveelheid gestructureerde en ongestructureerde klantendata waar alle departementen toegang toe zouden moeten hebben.
Verouderde infrastructuur

Maar net daar knelde het technologische schoentje. Uit een intern onderzoek en een gap assessment bleek dat we niet over de middelen beschikten om de vereiste data te verwerken, waardoor we geen complexere usecases konden ontwikkelen. Ons on-premises dataplatform werd jaren geleden ontworpen als datawarehouse waarin gegevens maandelijks geüpdatet werden.
Doorheen de jaren hebben we ons platform opgeschaald om dagelijkse updates te ondersteunen, maar het bleef inadequaat voor geavanceerde realtime analyses. We hadden ook nood aan meer schaalbaarheid en elasticiteit om verschillende soorten en grote hoeveelheden data op te slaan. Ons eerder dataplatform ondersteunde geen ongestructureerde data, zoals video's, afbeeldingen en weergegevens, wat ons ernstig beperkte bij de ontwikkeling van nieuwe, innoverende producten.
Bovendien waren we niet in staat om automatiseringsprocessen te implementeren of zelfs relatief eenvoudige taken uit te voeren die modernere dataplatforms wel aankunnen, zoals het tijdig genereren van basisrapporten.
Het feit dat we nog altijd gebruikmaakten van decennia oude technologieën voor datasets illustreert hoe dringend we onze architectuur en technologie moesten vernieuwen. We wisten dat we met cloudtechnologie onze kernsystemen zouden moderniseren en onze schaalbaarheid en elasticiteit zouden verhogen.
Hulp van techgiganten
Gezien de omvang van dit project hadden we externe expertise en tools nodig. We kozen om verschillende redenen voor Microsoft als ons doelsysteem voor de bouw van ons nieuwe dataplatform. AG Insurance maakt immers al gebruik van diverse technologieën binnen de Microsoft-datastack en beschikt over on-premises datawarehouse-functionaliteiten zoals Power BI, SSAS en SQL Server.
Maar we waren vooral geïntrigeerd door de visie en toewijding van Microsoft om voortdurend te investeren in de ontwikkeling van hun producten. Een kleine pilot met dummybestanden bevestigde onze overtuiging dat Microsoft de juiste keuze was en liet ons toe onze technologische behoeften opnieuw te evalueren, onze resourcevereisten te verfijnen en de mogelijke kosten van deze operatie beter te begroten.
Onze tweede partner is Hexaware. Zij staan ons al jaren bij voor de ontwikkeling en het onderhoud van ons on-premises dataplatform en stonden de voorbije jaren al garant voor expertise en betrouwbaarheid. Onze partners hebben de datastructuur opnieuw gecreëerd, de pipeline herschreven en de hele datageschiedenis van onze on-premises dataomgeving overgezet naar het nieuwe cloudplatform.
Dataplatform in opbouw
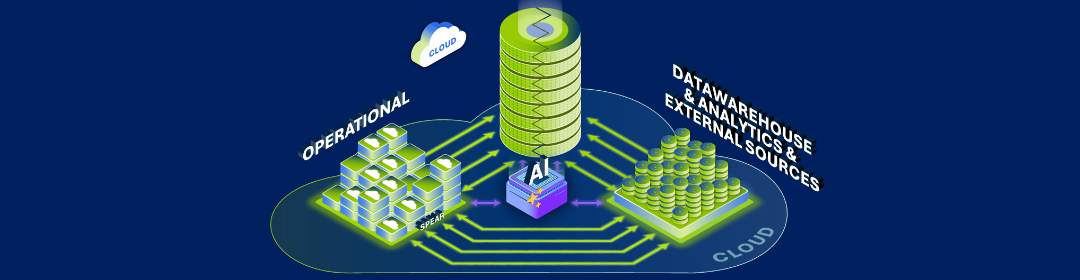
We bouwden ons nieuw dataplatform in Microsoft Azure Synapse Analytics. Het platform dat we voor ogen hadden, moest diverse opslaglagen en technische componenten integreren om automatisering en standaardisatie te bevorderen, ontwikkelingskosten te verlagen en onze inspanningen rondom datamanagement te monitoren.

Ons team implementeerde het architectuurframework met Microsoft Azure Databricks, gecombineerd met Microsoft Azure Data Lake Storage Gen2, om enorme hoeveelheden data te beheren en geavanceerde analyses te vergemakkelijken.
Daarnaast vertrouwden we op Azure SQL DB als centrale opslagplaats voor het configureren van het data automation framework, en Synapse Dedicated SQL Pools als publicatielaag voor de downstreamsystemen. We hebben ook Azure Data Factory ingezet om dataflows in kaart te brengen en om schaalbare ETL's visueel te kunnen bouwen. Tegelijkertijd hebben we met behulp van Microsoft Power BI en Azure tools zoals Databricks een self-service end-userzone gecreëerd, waar business users gebruik kunnen maken van de data die we klaarmaken voor rapportage.
Naast al deze Microsoft tools, creëerden we ons eigen framework bestaande uit een reeks technische diensten met behulp van PySpark. Dit framework maakt het mogelijk om snel en kosteneffectiefdata te uploaden in de lagere lagen.
Moeizame eerste testritten
Eens we onze doelarchitectuur gebouwd hadden, hebben we een eerste business line gemigreerd. We kozen voor een gefaseerde aanpak waarbij we 1 à 2 business lines of departementen migreerden, in plaats van een Big Bang. Hierdoor konden we het proces stap-per-stap beoordelen, de omgeving volledig testen en pijnpunten blootleggen. Wat ook gebeurde. We botsten op twee grote mankementen.
De eerste tekortkoming was onze teststrategie. Aanvankelijk wilden we de prestaties, pipelines en integratie van het nieuwe platform testen door de datageschiedenis van ons on-premises dataplatform naar onze nieuwe cloudomgeving te kopiëren en beide dataplatformen tegelijkertijd te laten draaien. Vergelijkbare resultaten van beide runs zouden wijzen op een succesvolle migratie van het ene platform naar het andere. Bij een afwijkend resultaat zouden we het probleem op het nieuwe platform kunnen opsporen en oplossen.
De test bracht inderdaad enkele verschillen aan het licht. Maar waar we de oorzaken op het nieuwe platform verwachtten te vinden, bleek al snel dat de verschillen door heel wat meer factoren veroorzaakt konden worden. Het opsporen en oplossen van de oorzaken kostte ons dus veel meer tijd en energie.
De tweede tekortkoming was de ondermaatse datakwaliteit in onze on-premisesomgeving. Ons nieuwe dataplatform heeft stringente datakwaliteitsinstellingen voor toekomstige uploads. We hadden echter niet verwacht dat deze instellingen foutieve datasets van ons on-premises dataplatform zouden blootleggen. Hierdoor konden we onze datakwaliteit verhogen, maar liepen we uiteraard vertraging op.
Nadat we deze hindernissen overwonnen, zetten we de migraties verder. Tegen maart 2024 zal heel ons analytische hebben en houden op het nieuwe platform draaien.
Instant rendement en langetermijnvoordelen
Hoewel de migratie nog steeds gaande is, plukken we er nu al de vruchten van. De laatste rapporten tonen een verlaging van de bedrijfskosten met 25% bij een constant businessvolume, een kortere time-to-market voor nieuwe businessprojecten en aanzienlijk lagere ontwikkelingskosten voor de opname van nieuwe data.
We hebben ook de doorlooptijd van batchactiviteiten verkort. Jobs en pipelines die eerder 10 uur duurden, worden in de cloud in 2 uur uitgevoerd. De Azure Data Lake Storage Gen2 heeft geleid tot enorme schaalbaarheidsvoordelen. Hierdoor kunnen we alles wat cruciaal is in de bovenste lagen opslaan en indien nodig de historiek heropbouwen. Bovendien kunnen we de workloadvariaties van pipelines in de lagere lagen via Azure Databricks, Data Factory en Synapse makkelijker beheren.
 - 3")
Ook de kwaliteit van onze data is verbeterd. We hebben nieuwe richtlijnen opgesteld en de bijhorende instellingen en metadata op ons nieuwe dataplatform geïmplementeerd. Alle departementen zijn contractueel gebonden aan deze normen.
Bouwstenen voor toekomstige innovatie
Het belangrijkste voordeel is dat we nu onbeperkt kunnen innoveren om onze bedrijfsprocessen, diensten en klantervaringen te verbeteren. Zo zal het nieuwe dataplatform ons binnenkort in staat stellen om claimprocessen te vergemakkelijken. Klanten kunnen dan foto's uploaden als bewijs van hun schade. Een algoritme vergelijkt dan de schade op de beelden met een enorme hoeveelheid data, beoordeelt de kosten van de schade en betaalt die dan uit.
Of wat dacht je van het in realtime personaliseren van menselijke interactie? In de toekomst zouden we de emotionele basistoestand van de klant kunnen bepalen op basis van eerdere interacties met onze diensten. Als een klant tijdens een stressvol moment contact met ons opneemt, zouden we op basis van toon of stemvolume kunnen detecteren of de klant afwijkt van die basistoestand. Dankzij deze inzichten zouden onze collega's hun communicatiestijl dan kunnen aanpassen.
Conclusie
Door de kracht van data en cloudtechnologie te omarmen, hebben we de basis gelegd om deze innovaties te verkennen. Daar zijn we nu volop mee bezig. We houden je op de hoogte van onze ontwikkelingen.
We wisten dat we het potentieel van dit nieuwe dataplatform echter alleen volledig zouden kunnen benutten door het te koppelen aan een operationele infrastructuur die even futureproof is. Mede daarom hebben we een unieke replatforming uitgevoerd. Ontdek meer over dit historisch project of lees een van de andere interessante artikels.